Penn Engineers have uncovered an unexpected pattern in how neural networks — the systems leading today’s AI revolution — learn, suggesting an answer to one of the most important unanswered questions in AI: why these methods work so well.
Inspired by biological neurons, neural networks are computer programs that take in data and train themselves by repeatedly making small modifications to the weights or parameters that govern their output, much like neurons adjusting their connections to one another. The final result is a model that allows the network to predict on data it has not seen before. Neural networks are being used today in essentially all fields of science and engineering, from medicine to cosmology, identifying potentially diseased cells and discovering new galaxies.
In a new paper published in the Proceedings of the National Academy of Sciences (PNAS), Pratik Chaudhari, Assistant Professor in Electrical and Systems Engineering (ESE) and core faculty at the General Robotics, Automation, Sensing and Perception (GRASP) Lab, and co-author James Sethna, James Gilbert White Professor of Physical Sciences at Cornell University, show that neural networks, no matter their design, size or training recipe, follow the same route from ignorance to truth when presented with images to classify.
Jialin Mao, a doctoral student in Applied Mathematics and Computational Science at the University of Pennsylvania School of Arts & Sciences, is the paper’s lead author.
“Suppose the task is to identify pictures of cats and dogs,” says Chaudhari. “You might use the whiskers to classify them, while another person might use the shape of the ears — you would presume that different networks would use the pixels in the images in different ways, and some networks certainly achieve better results than others, but there is a very strong commonality in how they all learn. This is what makes the result so surprising.”
The result not only illuminates the inner workings of neural networks, but gestures toward the possibility of developing hyper-efficient algorithms that could classify images in a fraction of the time, at a fraction of the cost. Indeed, one of the highest costs associated with AI is the immense computational power required to develop neural networks. “These results suggest that there may exist new ways to train them,” says Chaudhari.
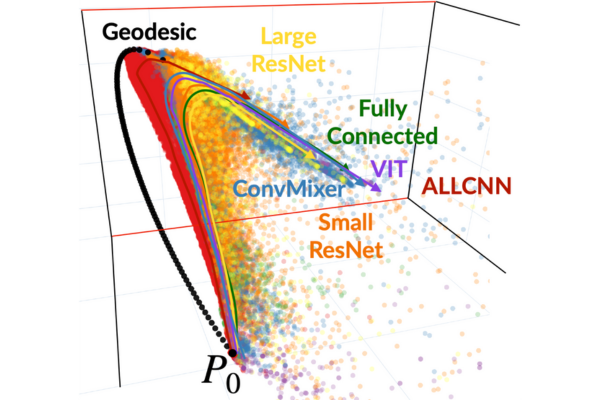
To illustrate the potential of this new method, Chaudhari suggests imagining the networks as trying to chart a course on a map. “Let us imagine two points,” he says. “Ignorance, where the network does not know anything about the correct labels, and Truth, where it can correctly classify all images. Training a network corresponds to charting a path between Ignorance and Truth in probability space — in billions of dimensions. But it turns out that different networks take the same path, and this path is more like three-, four-, or five-dimensional.”
In other words, despite the staggering complexity of neural networks, classifying images — one of the foundational tasks for AI systems — requires only a small fraction of that complexity. “This is actually evidence that the details of the network design, size or training recipes matter less than we think,” says Chaudhari.
To arrive at these insights, Chaudhari and Sethna borrowed tools from information geometry, a field that brings together geometry and statistics. By treating each network as a distribution of probabilities, the researchers were able to make a true apples-to-apples comparison among the networks, revealing their unexpected, underlying similarities. “Because of the peculiarities of high-dimensional spaces, all points are far away from one another,” says Chaudhari. “We developed more sophisticated tools that give us a cleaner picture of the networks’ differences.”
Using a wide variety of techniques, the team trained hundreds of thousands of networks, of many different varieties, including multi-layer perceptrons, convolutional and residual networks, and the transformers that are at the heart of systems like ChatGPT. “Then, this beautiful picture emerged,” says Chaudhari. “The output probabilities of these networks were neatly clustered together on these thin manifolds in gigantic spaces.” In other words, the paths that represented the networks’ learning aligned with one another, showing that they learned to classify images the same way.
Chaudhari offers two potential explanations for this surprising phenomenon: first, neural networks are never trained on random assortments of pixels. “Imagine salt and pepper noise,” says Chaudhari. “That is clearly an image, but not a very interesting one — images of actual objects like people and animals are a tiny, tiny subset of the space of all possible images.” Put differently, asking a neural network to classify images that matter to humans is easier than it seems, because there are many possible images the network never has to consider.
Second, the labels neural networks use are somewhat special. Humans group objects into broad categories, like dogs and cats, and do not have separate words for every particular member of every breed of animals. “If the networks had to use all the pixels to make predictions,” says Chaudhari, “then the networks would have figured out many, many different ways.” But the features that distinguish, say, cats and dogs are themselves low-dimensional. “We believe these networks are finding the same relevant features,” adds Chaudhari, likely by identifying commonalities like ears, eyes, markings and so on.
Discovering an algorithm that will consistently find the path needed to train a neural network to classify images using just a handful of inputs is an unresolved challenge. “This is the billion-dollar question,” says Chaudhari. “Can we train neural networks cheaply? This paper gives evidence that we might be able to. We just don’t know how.”
This study was conducted at the University of Pennsylvania School of Engineering and Applied Science and Cornell University. It was supported by grants from the National Science Foundation, National Institutes of Health, the Office of Naval Research, Eric and Wendy Schmidt AI in Science Postdoctoral Fellowship and cloud computing credits from Amazon Web Services.
Other co-authors include Rahul Ramesh at Penn Engineering; Rubing Yang at the University of Pennsylvania School of Arts & Sciences; Itay Griniasty and Han Kheng Teoh at Cornell University; and Mark K. Transtrum at Brigham Young University.